Natural Language Processing#

Bag of Words#
Bag of Words is a method used to represent text in a numerical format.
The frequency of words within documents is key.
Text structures like chapters, paragraphs, and grammar are ignored.
Splits text based on spaces and punctuation.
Document: A single piece of textual data.
Corpus: The collection of all documents, representing the entire dataset.
Steps:
Tokenization: Split each document into individual words.
Vocabulary: Create a collection of all unique words across all documents.
Encoding: Represent each document by the frequency of its words from the vocabulary.
CountVectorizer()#
corpus = ['How are you?',
'How old are you?',
'What is your name?']
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
cv.fit(corpus)
CountVectorizer()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
CountVectorizer()
The whole words in the corpus in alphabetical order.
# aplhabetical order
cv.vocabulary_
{'how': 1,
'are': 0,
'you': 6,
'old': 4,
'what': 5,
'is': 2,
'your': 7,
'name': 3}
vocabulary_list = []
for i in range(len(cv.vocabulary_)):
for key, value in cv.vocabulary_.items():
if value == i:
vocabulary_list.append(key)
vocabulary_list
['are', 'how', 'is', 'name', 'old', 'what', 'you', 'your']
The number of words in the whole corpus.
len(cv.vocabulary_)
8
The transform() method returns the numerical representation of each document
It returns a sparse matrix
Use toarray() method to convert it to an array
1 stands for existence of the corresponding word in the vocabulary in the document.
0 stands for non-existence of the corresponding word in the vocabulary in the document.
cv.transform(corpus)
<3x8 sparse matrix of type '<class 'numpy.int64'>'
with 11 stored elements in Compressed Sparse Row format>
cv.transform(corpus).toarray()
array([[1, 1, 0, 0, 0, 0, 1, 0],
[1, 1, 0, 0, 1, 0, 1, 0],
[0, 0, 1, 1, 0, 1, 0, 1]])
import pandas as pd
pd.DataFrame(cv.transform(corpus).toarray(), columns=vocabulary_list)
| are | how | is | name | old | what | you | your | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 |
cv.transform(['I am here']).toarray()
array([[0, 0, 0, 0, 0, 0, 0, 0]])
cv.transform(['How do you do?']).toarray()
array([[0, 1, 0, 0, 0, 0, 1, 0]])
YouTube Spam Collection#
https://archive.ics.uci.edu/dataset/380/youtube+spam+collection
# pip install ucimlrepo
Data#
from ucimlrepo import fetch_ucirepo
# fetch dataset
youtube_spam_collection = fetch_ucirepo(id=380)
# data (as pandas dataframes)
df_X = youtube_spam_collection.data.features
df_y = youtube_spam_collection.data.targets
df_X.tail()
| AUTHOR | DATE | CONTENT | |
|---|---|---|---|
| 1951 | Katie Mettam | 2013-07-13T13:27:39.441000 | I love this song because we sing it at Camp al... |
| 1952 | Sabina Pearson-Smith | 2013-07-13T13:14:30.021000 | I love this song for two reasons: 1.it is abou... |
| 1953 | jeffrey jules | 2013-07-13T12:09:31.188000 | wow |
| 1954 | Aishlin Maciel | 2013-07-13T11:17:52.308000 | Shakira u are so wiredo |
| 1955 | Latin Bosch | 2013-07-12T22:33:27.916000 | Shakira is the best dancer |
df_y.head()
| CLASS | |
|---|---|
| 0 | 1 |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
df_X.shape, df_y.shape
# metadata
type(youtube_spam_collection.metadata)
ucimlrepo.dotdict.dotdict
youtube_spam_collection.metadata.keys()
dict_keys(['uci_id', 'name', 'repository_url', 'data_url', 'abstract', 'area', 'tasks', 'characteristics', 'num_instances', 'num_features', 'feature_types', 'demographics', 'target_col', 'index_col', 'has_missing_values', 'missing_values_symbol', 'year_of_dataset_creation', 'last_updated', 'dataset_doi', 'creators', 'intro_paper', 'additional_info'])
youtube_spam_collection.metadata.abstract
'It is a public set of comments collected for spam research. It has five datasets composed by 1,956 real messages extracted from five videos that were among the 10 most viewed on the collection period.'
# variable information
youtube_spam_collection.variables
| name | role | type | demographic | description | units | missing_values | |
|---|---|---|---|---|---|---|---|
| 0 | VIDEO | ID | Categorical | None | None | None | no |
| 1 | COMMENT_ID | ID | Categorical | None | None | None | no |
| 2 | AUTHOR | Feature | Categorical | None | None | None | no |
| 3 | DATE | Feature | Categorical | None | None | None | no |
| 4 | CONTENT | Feature | Categorical | None | None | None | no |
| 5 | CLASS | Target | Binary | None | None | None | no |
df = pd.concat([df_X, df_y], axis=1)
df.tail()
| AUTHOR | DATE | CONTENT | CLASS | |
|---|---|---|---|---|
| 1951 | Katie Mettam | 2013-07-13T13:27:39.441000 | I love this song because we sing it at Camp al... | 0 |
| 1952 | Sabina Pearson-Smith | 2013-07-13T13:14:30.021000 | I love this song for two reasons: 1.it is abou... | 0 |
| 1953 | jeffrey jules | 2013-07-13T12:09:31.188000 | wow | 0 |
| 1954 | Aishlin Maciel | 2013-07-13T11:17:52.308000 | Shakira u are so wiredo | 0 |
| 1955 | Latin Bosch | 2013-07-12T22:33:27.916000 | Shakira is the best dancer | 0 |
df[df['CLASS'] == 0].head()
| AUTHOR | DATE | CONTENT | CLASS | |
|---|---|---|---|---|
| 7 | Bob Kanowski | 2013-11-28T12:33:27 | i turned it on mute as soon is i came on i jus... | 0 |
| 16 | Zielimeek21 | 2013-11-28T21:49:00 | I'm only checking the views | 0 |
| 20 | zhichao wang | 2013-11-29T02:13:56 | i think about 100 millions of the views come f... | 0 |
| 23 | Owen Lai | 2013-12-01T04:51:52 | just checking the views | 0 |
| 28 | Brandon Pryor | 2014-01-19T00:36:25 | I dont even watch it anymore i just come here ... | 0 |
X = df_X.CONTENT.values
X[0]
'Huh, anyway check out this you[tube] channel: kobyoshi02'
y = df_y.CLASS.values
y[0]
1
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
X_train.shape, X_test.shape
((1467,), (489,))
CountVectorizer()#
cv = CountVectorizer().fit(X_train)
X_train_bag = cv.transform(X_train)
X_test_bag = cv.transform(X_test)
X_train_bag.shape, X_test_bag.shape
((1467, 3679), (489, 3679))
cv.get_feature_names_out()
array(['00', '000', '002', ..., 'shoecollector314', 'usr', 'www'],
dtype=object)
min_df#
cv_min = CountVectorizer(min_df=10).fit(X_train)
X_min_train_bag = cv.transform(X_train)
X_min_test_bag = cv.transform(X_test)
X_min_train_bag.shape, X_min_test_bag.shape
((1467, 3679), (489, 3679))
max_df#
cv_max = CountVectorizer(max_df=5).fit(X_train)
X_max_train_bag = cv.transform(X_train)
X_max_test_bag = cv.transform(X_test)
X_max_train_bag.shape, X_max_test_bag.shape
((1467, 3679), (489, 3679))
stop_words#
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
list(ENGLISH_STOP_WORDS)[:10]
['go',
'wherein',
'first',
'down',
'should',
'although',
'can',
'system',
'last',
'already']
cv_sw = CountVectorizer(stop_words='english').fit(X_train)
X_sw_train_bag = cv.transform(X_train)
X_sw_test_bag = cv.transform(X_test)
X_sw_train_bag.shape, X_sw_test_bag.shape
((1467, 3679), (489, 3679))
Random Forest Classifier#
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=0)
rf.fit(X_train_bag, y_train)
rf.score(X_train_bag, y_train), rf.score(X_test_bag, y_test)
(1.0, 0.9427402862985685)
rf.predict(cv.transform(['It is really good.']))
array([0])
rf.predict(cv.transform(['I do not like it.']))
array([0])
rf.predict(cv.transform(['Youc an earn lots of money']))
array([0])
rf.predict(X_test_bag[:5])
array([0, 0, 1, 0, 0])
print(X_test[0])
I'm watching this in 2014
print(X_test[2])
Like this comment if you still jam out to this song after 4 years
Confusion Matrix#
from sklearn.metrics import confusion_matrix
from collections import Counter
Counter(y_test)
Counter({1: 263, 0: 226})
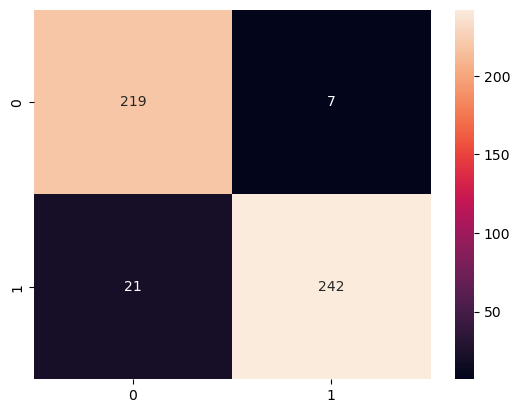
confusion_matrix(y_test, rf.predict(X_test_bag))
array([[219, 7],
[ 21, 242]])
import seaborn as sns
sns.heatmap(confusion_matrix(y_test, rf.predict(X_test_bag)), annot=True, fmt='d');
tf-idf#
Term Frequency-Inverse Document Frequency
tf-idf is a numerical statistic that reflects the importance of a word in a document relative to a collection of documents (corpus).
A word receives a higher weight if it frequently appears in a specific document but is rare across other documents.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer().fit(X_train)
X_train_tfidf = tfidf.transform(X_train)
X_test_tfidf = tfidf.transform(X_test)
X_train_tfidf.shape, X_test_tfidf.shape
((1467, 3679), (489, 3679))
X_train_tfidf[0].toarray()
array([[0., 0., 0., ..., 0., 0., 0.]])
for i in X_train_tfidf[0].toarray()[0]:
if i != 0:
print(i)
0.3738993842265373
0.42706490679643794
0.3752264208041245
0.3301365281288447
0.4462904256050391
0.4783875811481708
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=0)
rf.fit(X_train_tfidf, y_train)
rf.score(X_train_tfidf, y_train), rf.score(X_test_tfidf, y_test)
(1.0, 0.9406952965235174)
Sentiment Analysis#
A pre-trained model is used to classify a given string as either positive or negative in sentiment.
from nltk.sentiment import SentimentIntensityAnalyzer
sia = SentimentIntensityAnalyzer()
sia.polarity_scores('It is very useful.')
{'neg': 0.0, 'neu': 0.484, 'pos': 0.516, 'compound': 0.4927}
sia.polarity_scores('I will go there.')
{'neg': 0.0, 'neu': 1.0, 'pos': 0.0, 'compound': 0.0}
sia.polarity_scores('It is very ugly.')
{'neg': 0.545, 'neu': 0.455, 'pos': 0.0, 'compound': -0.5563}
Wordcloud#
https://amueller.github.io/word_cloud/
Default#
The algorithm might give more weight to the ranking of the words than their actual frequencies, depending on the max_font_size and the scaling heuristic.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
text = 'NY NY NY NJ TX TX CA CA CA CA CA IL MA'
wc = WordCloud(background_color='black', random_state=0, max_font_size=300, repeat=True)
wc.generate(text)
plt.imshow(wc, interpolation='bilinear')
plt.axis('off');

# colormap: rocket
wc = WordCloud(background_color='white', random_state=0, max_font_size=300, repeat=False, colormap='rocket')
wc.generate(text)
plt.imshow(wc, interpolation='bilinear')
plt.axis('off');

# colormap: rocket
wc = WordCloud(background_color='black', random_state=0, max_font_size=300, repeat=True, colormap='Reds')
wc.generate(text)
plt.imshow(wc, interpolation='bilinear')
plt.axis('off');

# weights
wc.words_
{'CA': 1.0, 'NY': 0.6, 'TX': 0.4, 'NJ': 0.2, 'IL': 0.2, 'MA': 0.2}
wc.layout_
[(('CA', 1.0), 268, (1, 53), None, 'rgb(255, 238, 231)'),
(('NY', 0.6), 109, (60, 104), None, 'rgb(252, 137, 105)'),
(('TX', 0.4), 64, (2, 1), None, 'rgb(119, 4, 15)'),
(('NJ', 0.2), 64, (63, 19), 2, 'rgb(250, 104, 73)'),
(('IL', 0.2), 64, (58, 352), 2, 'rgb(188, 20, 26)'),
(('MA', 0.2), 64, (3, 342), 2, 'rgb(111, 2, 14)'),
(('CA', 0.2), 62, (148, 1), None, 'rgb(252, 167, 139)'),
(('NY', 0.12), 60, (154, 258), None, 'rgb(251, 115, 83)'),
(('TX', 0.08000000000000002), 49, (19, 204), None, 'rgb(252, 166, 137)'),
(('NJ', 0.04000000000000001), 44, (138, 137), None, 'rgb(251, 113, 81)'),
(('IL', 0.04000000000000001), 44, (127, 367), 2, 'rgb(255, 235, 226)'),
(('MA', 0.04000000000000001), 41, (28, 132), None, 'rgb(211, 32, 32)'),
(('CA', 0.04000000000000001), 35, (77, 10), None, 'rgb(238, 58, 44)'),
(('NY', 0.024000000000000004), 34, (140, 185), None, 'rgb(252, 189, 164)'),
(('TX', 0.016000000000000004), 29, (118, 357), None, 'rgb(144, 10, 18)'),
(('NJ', 0.008000000000000002), 29, (39, 190), 2, 'rgb(187, 20, 26)'),
(('IL', 0.008000000000000002), 29, (77, 283), 2, 'rgb(105, 0, 13)'),
(('MA', 0.008000000000000002), 29, (98, 212), 2, 'rgb(254, 227, 215)'),
(('CA', 0.008000000000000002), 29, (100, 168), 2, 'rgb(254, 225, 211)'),
(('NY', 0.004800000000000001), 29, (1, 319), 2, 'rgb(121, 4, 15)'),
(('TX', 0.003200000000000001), 28, (89, 357), None, 'rgb(252, 175, 147)'),
(('NJ', 0.0016000000000000005), 28, (48, 24), None, 'rgb(252, 165, 136)'),
(('IL', 0.0016000000000000005), 24, (159, 14), None, 'rgb(253, 205, 185)'),
(('MA', 0.0016000000000000005), 24, (67, 230), 2, 'rgb(111, 2, 14)'),
(('CA', 0.0016000000000000003), 24, (8, 25), 2, 'rgb(254, 231, 219)'),
(('NY', 0.0009600000000000001), 24, (168, 374), 2, 'rgb(140, 9, 18)'),
(('TX', 0.0006400000000000002), 22, (136, 290), None, 'rgb(222, 43, 37)'),
(('NJ', 0.0003200000000000001), 22, (1, 240), None, 'rgb(252, 179, 152)'),
(('IL', 0.0003200000000000001), 22, (1, 210), None, 'rgb(154, 12, 20)'),
(('MA', 0.0003200000000000001), 22, (136, 263), None, 'rgb(243, 76, 55)'),
(('CA', 0.0003200000000000001), 22, (138, 111), None, 'rgb(254, 231, 220)'),
(('NY', 0.00019200000000000003), 22, (114, 1), 2, 'rgb(243, 73, 53)'),
(('TX', 0.00012800000000000005), 22, (48, 1), 2, 'rgb(252, 189, 164)'),
(('NJ', 6.400000000000002e-05), 20, (4, 74), None, 'rgb(189, 21, 26)'),
(('IL', 6.400000000000002e-05), 20, (19, 1), 2, 'rgb(193, 22, 27)'),
(('MA', 6.400000000000002e-05), 20, (182, 315), None, 'rgb(255, 238, 230)'),
(('CA', 6.400000000000002e-05), 20, (182, 75), None, 'rgb(255, 241, 234)'),
(('NY', 3.840000000000001e-05), 20, (167, 202), 2, 'rgb(178, 18, 24)'),
(('TX', 2.5600000000000012e-05), 20, (34, 326), 2, 'rgb(252, 148, 116)'),
(('NJ', 1.2800000000000006e-05), 20, (23, 221), 2, 'rgb(241, 65, 48)'),
(('IL', 1.2800000000000006e-05), 20, (58, 135), 2, 'rgb(212, 33, 33)'),
(('MA', 1.2800000000000006e-05), 20, (136, 163), 2, 'rgb(188, 20, 26)'),
(('CA', 1.2800000000000005e-05), 20, (112, 122), 2, 'rgb(240, 61, 45)'),
(('NY', 7.680000000000003e-06), 18, (14, 375), None, 'rgb(254, 233, 223)'),
(('TX', 5.120000000000002e-06), 18, (148, 370), None, 'rgb(253, 208, 188)'),
(('NJ', 2.560000000000001e-06), 18, (60, 286), 2, 'rgb(242, 70, 51)'),
(('IL', 2.560000000000001e-06), 18, (79, 165), 2, 'rgb(253, 202, 181)'),
(('MA', 2.560000000000001e-06), 18, (176, 291), 2, 'rgb(176, 18, 23)'),
(('CA', 2.5600000000000013e-06), 17, (54, 236), None, 'rgb(218, 39, 35)'),
(('NY', 1.5360000000000008e-06), 17, (135, 50), None, 'rgb(255, 236, 227)'),
(('TX', 1.0240000000000005e-06), 17, (46, 112), None, 'rgb(253, 213, 196)'),
(('NJ', 5.120000000000002e-07), 17, (92, 97), 2, 'rgb(142, 9, 18)'),
(('IL', 5.120000000000002e-07), 17, (49, 58), 2, 'rgb(222, 43, 37)'),
(('MA', 5.120000000000002e-07), 17, (135, 37), 2, 'rgb(232, 52, 41)'),
(('CA', 5.120000000000002e-07), 17, (18, 67), None, 'rgb(254, 216, 199)'),
(('NY', 3.0720000000000016e-07), 15, (31, 340), None, 'rgb(206, 26, 30)'),
(('TX', 2.0480000000000011e-07), 15, (179, 50), 2, 'rgb(252, 178, 150)'),
(('NJ', 1.0240000000000006e-07), 15, (135, 17), None, 'rgb(252, 153, 122)'),
(('IL', 1.0240000000000006e-07), 15, (79, 339), 2, 'rgb(242, 71, 52)'),
(('MA', 1.0240000000000006e-07), 15, (160, 70), 2, 'rgb(212, 33, 33)'),
(('CA', 1.0240000000000006e-07), 15, (180, 248), 2, 'rgb(178, 18, 24)'),
(('NY', 6.144000000000003e-08), 14, (54, 328), None, 'rgb(253, 204, 184)'),
(('TX', 4.0960000000000024e-08), 14, (45, 182), None, 'rgb(252, 195, 171)'),
(('NJ', 2.0480000000000012e-08), 14, (154, 121), None, 'rgb(165, 15, 21)'),
(('IL', 2.0480000000000012e-08), 14, (102, 1), None, 'rgb(196, 22, 28)'),
(('MA', 2.0480000000000012e-08), 14, (37, 388), 2, 'rgb(254, 234, 225)'),
(('CA', 2.0480000000000012e-08), 14, (1, 340), None, 'rgb(248, 95, 67)'),
(('NY', 1.2288000000000007e-08), 14, (95, 233), 2, 'rgb(241, 67, 49)'),
(('TX', 8.192000000000005e-09), 13, (176, 22), None, 'rgb(252, 162, 133)'),
(('NJ', 4.096000000000002e-09), 13, (111, 99), 2, 'rgb(181, 19, 24)'),
(('IL', 4.096000000000002e-09), 13, (70, 100), 2, 'rgb(253, 205, 185)'),
(('MA', 4.096000000000002e-09), 13, (164, 324), 2, 'rgb(113, 2, 14)'),
(('CA', 4.096000000000002e-09), 12, (36, 24), None, 'rgb(126, 6, 16)'),
(('NY', 2.4576000000000015e-09), 12, (24, 258), 2, 'rgb(255, 243, 237)'),
(('TX', 1.638400000000001e-09), 12, (118, 54), None, 'rgb(248, 95, 67)'),
(('NJ', 8.192000000000005e-10), 12, (9, 1), None, 'rgb(241, 65, 48)'),
(('IL', 8.192000000000005e-10), 12, (31, 177), None, 'rgb(252, 178, 150)'),
(('MA', 8.192000000000005e-10), 12, (4, 264), 2, 'rgb(251, 114, 82)'),
(('CA', 8.192000000000005e-10), 12, (24, 202), 2, 'rgb(255, 242, 235)'),
(('NY', 4.915200000000003e-10), 12, (69, 164), 2, 'rgb(169, 16, 22)'),
(('TX', 3.2768000000000026e-10), 12, (84, 17), None, 'rgb(182, 19, 25)'),
(('NJ', 1.6384000000000013e-10), 12, (78, 1), 2, 'rgb(252, 178, 150)'),
(('IL', 1.6384000000000013e-10), 12, (81, 141), 2, 'rgb(222, 43, 37)'),
(('MA', 1.6384000000000013e-10), 12, (155, 35), 2, 'rgb(132, 7, 17)'),
(('CA', 1.6384000000000013e-10), 12, (137, 316), 2, 'rgb(213, 34, 33)'),
(('NY', 9.830400000000007e-11), 12, (72, 196), 2, 'rgb(252, 147, 115)'),
(('TX', 6.553600000000006e-11), 12, (48, 39), 2, 'rgb(243, 73, 53)'),
(('NJ', 3.276800000000003e-11), 11, (2, 96), None, 'rgb(252, 160, 130)'),
(('IL', 3.276800000000003e-11), 11, (104, 285), None, 'rgb(252, 158, 128)'),
(('MA', 3.276800000000003e-11), 11, (98, 304), 2, 'rgb(253, 213, 196)'),
(('CA', 3.276800000000003e-11), 11, (128, 354), 2, 'rgb(252, 151, 119)'),
(('NY', 1.9660800000000016e-11), 11, (97, 121), 2, 'rgb(252, 173, 144)'),
(('TX', 1.3107200000000013e-11), 11, (111, 17), None, 'rgb(134, 8, 17)'),
(('NJ', 6.553600000000006e-12), 11, (145, 66), 2, 'rgb(252, 137, 105)'),
(('IL', 6.553600000000006e-12), 11, (190, 202), None, 'rgb(254, 227, 215)'),
(('MA', 6.553600000000006e-12), 11, (139, 1), None, 'rgb(251, 114, 82)'),
(('CA', 6.5536000000000055e-12), 11, (183, 267), 2, 'rgb(254, 225, 211)'),
(('NY', 3.932160000000003e-12), 10, (131, 222), None, 'rgb(252, 129, 97)'),
(('TX', 2.6214400000000022e-12), 10, (191, 100), None, 'rgb(221, 42, 37)'),
(('NJ', 1.3107200000000011e-12), 10, (36, 120), None, 'rgb(238, 58, 44)'),
(('IL', 1.3107200000000011e-12), 10, (35, 357), None, 'rgb(254, 234, 225)'),
(('MA', 1.3107200000000011e-12), 10, (152, 305), None, 'rgb(252, 196, 173)'),
(('CA', 1.3107200000000013e-12), 10, (69, 3), None, 'rgb(252, 141, 109)'),
(('NY', 7.864320000000008e-13), 10, (131, 207), None, 'rgb(142, 9, 18)'),
(('TX', 5.242880000000005e-13), 10, (92, 350), None, 'rgb(224, 44, 38)'),
(('NJ', 2.6214400000000027e-13), 10, (91, 286), None, 'rgb(252, 196, 173)'),
(('IL', 2.6214400000000027e-13), 10, (66, 247), 2, 'rgb(252, 128, 96)'),
(('MA', 2.6214400000000027e-13), 10, (39, 55), 2, 'rgb(181, 19, 24)'),
(('CA', 2.6214400000000027e-13), 10, (1, 230), 2, 'rgb(150, 11, 19)'),
(('NY', 1.5728640000000015e-13), 10, (155, 217), 2, 'rgb(253, 202, 181)'),
(('TX', 1.0485760000000011e-13), 10, (80, 50), 2, 'rgb(253, 199, 178)'),
(('NJ', 5.2428800000000056e-14), 10, (67, 333), 2, 'rgb(239, 60, 44)'),
(('IL', 5.2428800000000056e-14), 10, (162, 290), 2, 'rgb(252, 146, 114)'),
(('MA', 5.2428800000000056e-14), 10, (82, 221), 2, 'rgb(254, 228, 216)'),
(('CA', 5.2428800000000056e-14), 10, (184, 391), 2, 'rgb(254, 218, 202)'),
(('NY', 3.1457280000000035e-14), 10, (154, 275), 2, 'rgb(252, 130, 98)'),
(('TX', 2.0971520000000024e-14), 10, (96, 343), 2, 'rgb(177, 18, 24)'),
(('NJ', 1.0485760000000012e-14), 10, (46, 224), 2, 'rgb(247, 91, 64)'),
(('IL', 1.0485760000000012e-14), 10, (99, 274), 2, 'rgb(216, 36, 34)'),
(('MA', 1.0485760000000012e-14), 10, (121, 368), 2, 'rgb(182, 19, 25)'),
(('CA', 1.0485760000000012e-14), 10, (24, 155), 2, 'rgb(165, 15, 21)'),
(('NY', 6.291456000000007e-15), 10, (48, 290), 2, 'rgb(175, 17, 23)'),
(('TX', 4.194304000000005e-15), 10, (143, 358), 2, 'rgb(254, 234, 225)'),
(('NJ', 2.0971520000000026e-15), 9, (1, 388), None, 'rgb(252, 195, 171)'),
(('IL', 2.0971520000000026e-15), 9, (116, 175), 2, 'rgb(173, 17, 23)'),
(('MA', 2.0971520000000026e-15), 9, (89, 390), 2, 'rgb(166, 15, 21)'),
(('CA', 2.0971520000000026e-15), 9, (30, 71), None, 'rgb(250, 104, 73)'),
(('NY', 1.2582912000000015e-15), 9, (127, 102), 2, 'rgb(255, 240, 232)'),
(('TX', 8.38860800000001e-16), 9, (154, 204), 2, 'rgb(200, 23, 28)'),
(('NJ', 4.194304000000005e-16), 9, (92, 368), 2, 'rgb(150, 11, 19)'),
(('IL', 4.194304000000005e-16), 9, (56, 343), None, 'rgb(179, 18, 24)'),
(('MA', 4.194304000000005e-16), 8, (192, 2), None, 'rgb(117, 3, 15)'),
(('CA', 4.194304000000005e-16), 8, (1, 356), None, 'rgb(172, 17, 23)'),
(('NY', 2.516582400000003e-16), 8, (167, 253), 2, 'rgb(253, 208, 188)'),
(('TX', 1.6777216000000022e-16), 8, (41, 4), None, 'rgb(252, 160, 130)'),
(('NJ', 8.388608000000011e-17), 8, (28, 388), None, 'rgb(130, 7, 17)'),
(('IL', 8.388608000000011e-17), 8, (57, 133), None, 'rgb(252, 143, 111)'),
(('MA', 8.388608000000011e-17), 8, (18, 1), None, 'rgb(234, 54, 42)'),
(('CA', 8.388608000000011e-17), 8, (54, 388), None, 'rgb(209, 30, 31)'),
(('NY', 5.033164800000006e-17), 8, (112, 233), 2, 'rgb(252, 133, 101)'),
(('TX', 3.3554432000000047e-17), 8, (85, 99), None, 'rgb(212, 33, 33)'),
(('NJ', 1.6777216000000023e-17), 7, (173, 81), None, 'rgb(109, 1, 14)'),
(('IL', 1.6777216000000023e-17), 7, (176, 388), None, 'rgb(251, 117, 85)'),
(('MA', 1.6777216000000023e-17), 7, (1, 201), None, 'rgb(251, 115, 83)'),
(('CA', 1.6777216000000023e-17), 7, (129, 187), 2, 'rgb(240, 61, 45)'),
(('NY', 1.0066329600000013e-17), 7, (19, 262), None, 'rgb(217, 37, 35)'),
(('TX', 6.7108864000000095e-18), 7, (53, 163), None, 'rgb(252, 143, 111)'),
(('NJ', 3.3554432000000048e-18), 7, (130, 136), None, 'rgb(254, 227, 214)'),
(('IL', 3.3554432000000048e-18), 7, (178, 15), None, 'rgb(240, 63, 46)'),
(('MA', 3.3554432000000048e-18), 7, (60, 103), 2, 'rgb(254, 225, 211)'),
(('CA', 3.3554432000000048e-18), 7, (93, 1), None, 'rgb(252, 173, 144)'),
(('NY', 2.0132659200000028e-18), 7, (149, 220), None, 'rgb(188, 20, 26)'),
(('TX', 1.342177280000002e-18), 7, (5, 312), 2, 'rgb(249, 99, 70)'),
(('NJ', 6.71088640000001e-19), 7, (20, 42), None, 'rgb(255, 239, 232)'),
(('IL', 6.71088640000001e-19), 7, (77, 137), None, 'rgb(201, 24, 29)'),
(('MA', 6.71088640000001e-19), 7, (1, 52), None, 'rgb(124, 5, 16)'),
(('CA', 6.71088640000001e-19), 7, (46, 198), 2, 'rgb(252, 185, 159)'),
(('NY', 4.026531840000006e-19), 7, (81, 289), None, 'rgb(252, 194, 170)'),
(('TX', 2.684354560000004e-19), 7, (169, 156), None, 'rgb(194, 22, 27)'),
(('NJ', 1.342177280000002e-19), 7, (39, 257), None, 'rgb(250, 104, 73)'),
(('IL', 1.342177280000002e-19), 7, (50, 17), 2, 'rgb(252, 129, 97)'),
(('MA', 1.342177280000002e-19), 7, (1, 253), 2, 'rgb(252, 133, 101)'),
(('CA', 1.342177280000002e-19), 6, (166, 144), None, 'rgb(252, 128, 96)'),
(('NY', 8.053063680000012e-20), 6, (193, 61), None, 'rgb(142, 9, 18)'),
(('TX', 5.368709120000008e-20), 6, (161, 23), 2, 'rgb(252, 187, 161)'),
(('NJ', 2.684354560000004e-20), 6, (11, 332), None, 'rgb(252, 152, 121)'),
(('IL', 2.684354560000004e-20), 6, (54, 211), None, 'rgb(253, 209, 190)'),
(('MA', 2.684354560000004e-20), 6, (33, 191), None, 'rgb(182, 19, 25)'),
(('CA', 2.684354560000004e-20), 6, (22, 29), None, 'rgb(253, 199, 178)'),
(('NY', 1.6106127360000025e-20), 6, (193, 40), None, 'rgb(208, 29, 31)'),
(('TX', 1.0737418240000017e-20), 6, (91, 52), 2, 'rgb(252, 148, 116)'),
(('NJ', 5.368709120000009e-21), 6, (121, 47), None, 'rgb(252, 193, 168)'),
(('IL', 5.368709120000009e-21), 6, (65, 287), None, 'rgb(254, 227, 214)'),
(('MA', 5.368709120000009e-21), 6, (37, 369), None, 'rgb(254, 223, 208)'),
(('CA', 5.368709120000009e-21), 6, (90, 178), 2, 'rgb(252, 160, 130)'),
(('NY', 3.221225472000005e-21), 6, (100, 357), 2, 'rgb(134, 8, 17)'),
(('TX', 2.1474836480000036e-21), 6, (111, 189), 2, 'rgb(253, 206, 187)'),
(('NJ', 1.0737418240000018e-21), 6, (3, 85), 2, 'rgb(248, 93, 66)'),
(('IL', 1.0737418240000018e-21), 6, (97, 57), None, 'rgb(154, 12, 20)'),
(('MA', 1.0737418240000018e-21), 6, (59, 163), 2, 'rgb(252, 166, 137)'),
(('CA', 1.0737418240000018e-21), 6, (60, 17), 2, 'rgb(252, 147, 115)'),
(('NY', 6.442450944000011e-22), 6, (28, 222), None, 'rgb(241, 68, 50)'),
(('TX', 4.294967296000007e-22), 6, (193, 193), None, 'rgb(254, 233, 223)'),
(('NJ', 2.1474836480000035e-22), 6, (167, 216), 2, 'rgb(252, 133, 101)'),
(('IL', 2.1474836480000035e-22), 6, (164, 13), 2, 'rgb(252, 130, 98)'),
(('MA', 2.1474836480000035e-22), 6, (1, 109), None, 'rgb(252, 188, 162)'),
(('CA', 2.1474836480000035e-22), 6, (139, 225), 2, 'rgb(128, 6, 16)'),
(('NY', 1.2884901888000021e-22), 6, (142, 116), None, 'rgb(255, 244, 238)'),
(('TX', 8.589934592000015e-23), 6, (88, 304), 2, 'rgb(251, 125, 93)'),
(('NJ', 4.294967296000007e-23), 6, (95, 144), 2, 'rgb(254, 230, 218)'),
(('IL', 4.294967296000007e-23), 6, (50, 109), 2, 'rgb(254, 227, 214)'),
(('MA', 4.294967296000007e-23), 6, (29, 3), None, 'rgb(189, 21, 26)'),
(('CA', 4.294967296000008e-23), 5, (130, 163), None, 'rgb(253, 206, 187)'),
(('NY', 2.5769803776000046e-23), 5, (65, 230), None, 'rgb(252, 188, 162)'),
(('TX', 1.7179869184000033e-23), 5, (169, 166), None, 'rgb(254, 219, 204)'),
(('NJ', 8.589934592000017e-24), 5, (47, 243), None, 'rgb(251, 112, 80)'),
(('IL', 8.589934592000017e-24), 5, (148, 393), 2, 'rgb(240, 61, 45)'),
(('MA', 8.589934592000017e-24), 5, (96, 37), None, 'rgb(254, 226, 213)'),
(('CA', 8.589934592000015e-24), 5, (97, 167), 2, 'rgb(247, 89, 63)'),
(('NY', 5.153960755200009e-24), 5, (187, 80), None, 'rgb(254, 230, 218)'),
(('TX', 3.435973836800006e-24), 5, (76, 370), None, 'rgb(247, 89, 63)'),
(('NJ', 1.717986918400003e-24), 5, (124, 125), None, 'rgb(111, 2, 14)'),
(('IL', 1.717986918400003e-24), 5, (194, 14), None, 'rgb(226, 46, 39)'),
(('MA', 1.717986918400003e-24), 5, (76, 353), None, 'rgb(249, 96, 68)')]
Frequency#
wc = WordCloud(background_color='black', max_words=1000)
text = 'NY NY NY NY NY NY NJ TX TX CA CA CA CA CA IL'
freq_dict = {}
for i in text.split():
freq_dict[i] = freq_dict.get(i, 0) +1
wc.generate_from_frequencies(freq_dict)
plt.imshow(wc, interpolation="bilinear")
plt.axis("off");

Circular Shape#
This is an example from the documentation:
Create a word cloud using a single word that is repeated multiple times.
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = 'NY NY NY NJ TX TX CA CA CA CA CA IL MA'
x, y = np.ogrid[:300, :300]
mask = (x - 150) ** 2 + (y - 150) ** 2 > 130 ** 2
mask = 255 * mask.astype(int)
wc = WordCloud(background_color="white", repeat=True, mask=mask)
wc.generate(text)
plt.axis("off")
plt.imshow(wc, interpolation="bilinear")
plt.show()

np.ogrid ogrid returns an open multi-dimensional grid, which is essentially a range of values in a specified shape.
It’s like creating a grid of coordinates for calculations but more memory-efficient than a full meshgrid.
x, y = np.ogrid[:5, :5]
mask = (x - 1) ** 2 + (y - 2) ** 2 > 3 ** 2
mask = 255 * mask.astype(int)
mask
array([[ 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0],
[255, 255, 0, 255, 255]])
Alice Image#
from PIL import Image
import string
import random
alice_mask = np.array(Image.open("pict/alice_mask.png"))
text = ''
for i in range(5000):
text += random.choice(string.ascii_letters) + random.choice(string.ascii_letters) + ' '
freq_dict = {}
for i in text.split():
freq_dict[i] = freq_dict.get(i, 0) +1
wc = WordCloud(background_color="white", mask=alice_mask, max_font_size=50)
wc.generate_from_frequencies(freq_dict)
plt.imshow(wc, interpolation="bilinear")
plt.axis("off");
